목차
-
메모리를 따로 할당하지 않는 Tensor 객체 연산
-
메모리를 따로 할당하지 않을때 문제점
-
해결방안 : Contiguous 함수
-
정리
1. 메모리를 따로 할당하지 않는 Tensor 객체 연산
- narrow()
- view()
- expand()
- transpose()
- permute()
etc (찾는대로 추가필요)
-
위 목록에 있는 Tensor 겍체와 관련된 몇가지 연산들은 원본 데이터를 따로 메모리에 할당하여 복사하지 않고 원본 메모리 주소를 공유한다. 다시말해, Tensor 객체의 메타 정보만을 수정하기 때문에 offset과 stride가 새로운 모양을 갖는것 뿐이다. 그러므로 위의 연산을 거친 Tensor 객체 내 데이터를 변경하면 원본 Tensor 데이터도 함께 변경된다.
(== 같은 pointer 공유)
-
위 목록 연산들의 출력 객체는 non-contiguous 이다.
2. 메모리를 따로 할당하지 않을때 문제점
메모리를 따로 할당하지 않기 때문에 column 기준으로 축을 바꿔버려 추후 바뀐 축단위 포인터 연산이 필요할시 문제가 될 수 있다.
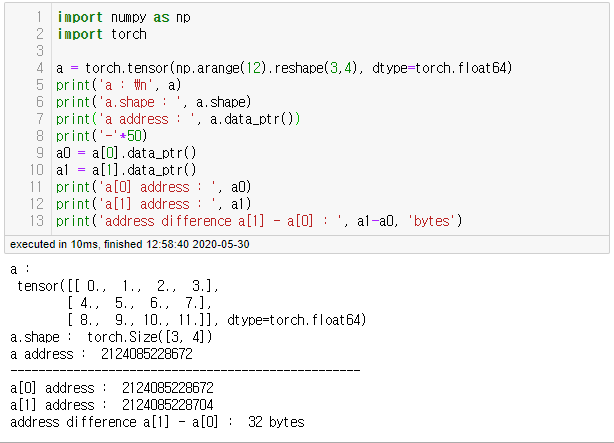
예를 들어, a = torch.tensor(np.arange(12).reshape(3,4), dtype=torch.float64) 가 있다고 하자,

위의 2D Tensor는 다음과 같이 8btyes(64bits)단위로 메모리에 연속적으로 할당된다.

즉, 우리가 생각하는 행렬모양이 아니라 일렬로 행단위로 늘어선 모양으로 메모리에 저장되기 때문에 값 0 다음 4를 찾아가려면, 8byte*4개=32bytes 만큼 움직여야 한다. 실제 연산 결과는 다음과 같다.

이를 transpose 연산을 하여 행과 열을 전치시킨 실제 연산 결과는 다음과 같다.

전치된 결과의 값 0과 4의 주소값 차이는 위에서 설명한대로 transpose연산은 원본 Tensor의 메타데이터를 변경했기 때문에 8byte일 것이다. 실제 결과는 아래와 같다.
이때, 결과는 non-contiguous(주소값 연속성이 고정)이므로 동일한 연산이 아닌 결과와 완전히 다른 축 모양을 원하는 연산들(예를 들어 view, permute)은 주소값 또한 다시 바꿔야하므로 Tensor 객체의 사이즈가 맞지 않다는 런타임 에러가 발생한다.
좀 더 쉽게 말하면 원본 행렬은 0에서 4로 가기 위해 32bytes가 필요했지만, 전치된 행렬은 8btyes가 필요하게 된다. 이때, 이 stride 차이가 불변이게 된다는 것이다.

3. 해결방안 : Contiguous 함수
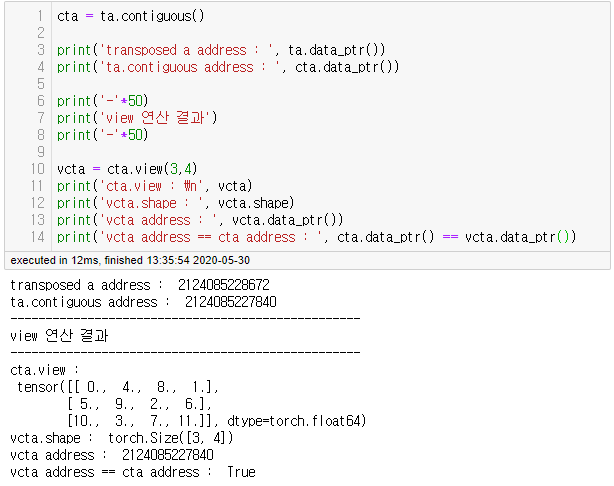
non-contiguous Tensor 객체의 경우 주소값 연속성이 불변인 것이 문제이므로 이를 contiguous()로 새로운 메모리 공간에 데이터를 복사하여 주소값 연속성을 가변적이게 만들어줄 수 있다. 아래 실제 결과에서 contiguous() 결과가 원본과 다른 새로운 주소로 할당된 것을 확인할 수 있다.

이렇게 새로 할당된 주소를 가지는 Tensor는 다시 주소값 stride를 변경하는 연산이 가능하게 된다. 이때, 새로운 메모리에 Tensor 객체를 복사하지 않는 연산들을 다시 사용하면 당연히 non-contiguous 결과를 얻는다.
4. 정리
-
view, transpose, permute 등과 같은 원본 Tensor의 메타데이터만 변경하는 함수들의 결과값은 non-contiguous Tensor 이다.
-
non-contiguous Tensor는 주소값 재배열 연산이 필요할 때 사용할 수 없다.
-
contiguous 함수로 새로운 메모리에 할당하여 contiguous Tensor로 변경하면 주소값 재배열이 가능하다.